
2026年采集浏览器推荐:9款数据采集工具对比
到2026年,开发网络爬虫远不止是获取网页内容这么简单。现在需要应对更多复杂情况:比如JavaScript渲染的网页、网站的反爬虫机制、验证码、访问频率限制、Cookie验证,以及越来越严格的设备指纹识别。
当人们提到网页采集工具时,通常指以下四类:
-
完全自主控制的浏览器自动化工具
比如Playwright、Puppeteer、Selenium。这些工具能直接操控浏览器,适合需要高度自定义或长期稳定运行的场景。 -
第三方托管的无头浏览器服务
例如Browserless、Bright Data。它们提供远程控制的无界面浏览器,你无需自己维护服务器集群,适合资源有限或希望快速部署的项目。 -
一站式反检测爬虫API
如ZenRows、ScraperAPI。这类服务内置代理切换、自动绕过验证码和反指纹技术,适合需要快速获取数据且不想处理技术细节的用户。
本文对比了9款主流工具,重点分析它们的使用难度、实际应用中的痛点,以及不同场景下的适用性,帮你快速选择最合适的方案。
快速对比(何时使用哪种工具)
|
工具 |
类别 |
最适合 |
|
反检测浏览器 |
配置文件隔离 + 本地 API,用于在独立浏览器环境中运行自动化程序 |
|
|
自动化库 |
现代的、大量使用 JavaScript 的爬虫程序,跨浏览器运行 |
|
|
自动化库 |
使用 DevTools 风格控件实现 Chrome/Firefox 自动化 |
|
|
自动化库 |
传统生态系统、广泛的语言支持、企业级测试堆栈 |
|
|
|
可视化采集工具 |
无需编程的网页数据采集,适合快速搭建爬虫与结构化数据提取 |
|
托管浏览器 |
“自带Playwright/Puppeteer”,无需运行浏览器 |
|
|
托管浏览器+网络 |
利用内置代理/验证码工具扩展浏览器自动化 |
|
|
托管API |
以最少的操作进行渲染和提取 |
|
|
托管API |
大规模数据获取,并可选择是否进行 JS 渲染 |
9款数据采集工具深度对比
1. Playwright
Playwright 是一个驱动真实浏览器的现代化自动化框架。根据 Playwright 官方文档,其支持 Chromium、Firefox 和 WebKit(Safari 引擎)。
优势:
-
对 JavaScript 密集型页面具有高可靠性(自动等待模式、强大的导航处理能力)
-
用于抓取 DOM 之外内容的实用原语:请求拦截、响应捕获、状态存储
-
支持多上下文并行处理(当需要在每台机器上运行多个会话时非常有用)
劣势:
-
你需要负责代理集成、指纹策略和扩展基础设施。
-
你需要制定切实可行的选择器漂移和数据质量保证计划。
最适合:希望最大程度控制且已拥有运行浏览器工作进程的工程流程的团队。
不建议使用的情况:需要一个“直接提供数据”的 API 且不想运行浏览器。
2. Puppeteer
Puppeteer 是一个提供高级 API 的 JavaScript 库,用于控制 Chrome 或 Firefox,详情请参阅 Puppeteer 的“什么是 Puppeteer?”指南。
优势:
-
熟悉的 DevTools 式思维模式
-
强大的 Chrome 优先自动化工作流生态系统(PDF、屏幕截图、性能跟踪)
劣势:
-
目前仍主要针对 Chromium 工作流进行优化。
-
与 Playwright 类似,需要自行维护基础设施并保持隐蔽性。
最适合:希望获得类似 DevTools 的控制功能,并且能够构建自己的扩展层的 Node 团队。
不建议使用的情况:希望开箱即用即可实现跨引擎一致性的用户。
3. Selenium
Selenium 是一套开源的浏览器自动化测试框架,最初用于Web测试,但由于它可以模拟真实用户操作(点击、输入、滚动、登录等),因此也被广泛用于网页数据采集/爬虫场景。
优势:
-
广泛的语言支持和企业级应用
-
适用于已部署 Selenium Grid 和 CI 流水线的组织
劣势:
-
性能较低,执行速度比API爬虫慢很多
-
虽然 Selenium 模拟浏览器。但网站可以识别WebDriver特征、自动化行为
-
如果要抓取类似应用程序的 UI,则可能需要花费时间调试时序问题和不稳定的选择器。
最适合:已具备 Selenium 专业知识/基础设施或需要广泛兼容性的组织。
不建议使用的情况:从零开始,并希望为现代单页应用程序 (SPA) 实现最快的迭代周期。
4. Octoparse
Octoparse(八爪鱼采集器) 是一款可视化网页数据采集工具,主打“无代码爬虫”,通过图形化界面即可完成网页结构识别、点击、翻页、登录等操作。它内置自动化规则与模板,适合不具备编程能力的用户快速搭建数据采集流程,并支持云端运行任务。
优势:
-
无需编程,通过可视化操作即可完成数据采集流程搭建
-
内置模板丰富,支持电商、社交媒体等常见网站的快速采集
-
支持云采集,可在云端运行任务,提升采集效率
劣势:
-
相比 Playwright、Selenium 等工具,自定义能力较弱
-
对于强反爬或复杂交互页面(如重度 JS 应用)成功率可能较低
最适合: 无编程基础但需要进行数据采集的用户,或希望快速搭建爬虫任务的中小团队。
不建议使用的情况: 需要高度定制化爬虫逻辑、复杂反爬对抗或大规模高并发数据采集的场景。
5. Browserless
Browserless 是一个托管的浏览器平台,可以理解为带有 API 和扩展支持的“远程 Chrome/Playwright 会话”。Browserless 在其网页抓取指南中详细解释了其方法和最佳实践。
优势:
-
无需管理浏览器集群,即可运行 Playwright/Puppeteer 式的自动化流程。
-
适用于需要真实交互(登录、点击、等待)但又不需要构建基础设施的工作流程。
劣势:
-
托管浏览器并不能解决机器人检测问题;你仍然需要合适的代理/会话策略。
-
仍然需要负责提取逻辑和选择器的质量保证。
最适合:希望保持代码级控制但外包浏览器基础设施的团队。
不建议使用的情况:如果主要障碍是“反机器人”,而不是“基础设施”,则应避免使用。
6. Bright Data Scraping Browser
这是一款托管浏览器产品,旨在托管浏览器上运行 Playwright/Selenium/Puppeteer 脚本,内置代理管理和 CAPTCHA 处理功能,详情请参阅 Bright Data Scraping Browser 产品页面。
优势:
-
专为应对实际挑战而设计:可扩展性、地理分布和解锁工作。
-
如果代理/CAPTCHA 开销占据了大量的工程时间,那么这款产品极具吸引力。
劣势:
-
如果你渲染所有内容,按使用量计费的费用可能会超出你的预期。
-
需要接受供应商管理会话、重试和流量的方式。
最适合:跨区域和目标进行高容量数据抓取,且基础设施和解锁成本实际存在的团队。
不建议使用的情况:仅抓取少量网站且成本是主要限制因素的团队。
7. ZenRows
ZenRows 是一款托管式爬虫 API,专注于“提供可用内容”,包括动态页面交互。ZenRows 在其 JavaScript 说明文档中详细记录了脚本交互(点击、等待、滚动等)。
优势:
-
API 优先:非常适合数据采集管道。
-
无需掌握浏览器底层架构,即可实现 JS 渲染和交互。
劣势:
-
相比自行运行 Playwright,底层控制能力较弱。
-
某些特殊情况(例如复杂的身份验证流程)仍然可能比较棘手。
最适合:希望将爬虫服务集成到大型 ETL 管道中的工程师。
不建议使用的情况:需要深度浏览器级调试和精确行为模拟的用户。
8. ScraperAPI
ScraperAPI 是一个代理+爬虫 API,可从目标 URL 返回内容,同时处理封禁和扩展。它支持 JavaScript 渲染,运作方式是通过自动运行无头浏览器来加载网页内容。具体的技术实现细节可以在《ScraperAPI JavaScript渲染概述》文档中找到详细说明。
优势:
-
集成简单:“发送 URL → 获取 HTML”。
-
适用于目标网站内容较为静态时进行大范围覆盖的情况。
劣势:
-
渲染是单独的模式;如果你的工作负载主要依赖 JavaScript,则成本和延迟可能会增加。
-
对于复杂的多步骤流程,你可能仍然需要一个库。
最适合:希望快速扩展抓取能力,并且仅在必要时启用浏览器渲染的团队。
不建议使用的情况:你的目标网站更像是应用程序而不是网页。
9. AdsPower
AdsPower 是一款反检测浏览器/指纹浏览器,专门设计用来创建完全独立的浏览器环境,隔离Cookie、存储数据和设备指纹信息。
AdsPower 提供了本地 API、RPA 和浏览器环境管理等功能,在需要保持不同账号或身份数据隔离的场景下非常实用。
对于数据采集来说,AdsPower 的主要作用是通过提供干净独立的浏览器环境和方便对接自动化的接口,帮助解决反检测问题。
点击免费体验 AdsPower,领取免费的浏览器环境!
优势:
-
浏览器环境隔离:可针对不同环境设置独立的浏览器指纹/Cookie/存储,有效防止网站通过关联 Cookie 或存储特征识别出采集行为。
-
低门槛 RPA 机器人:内置可视化 RPA 工具,无需深厚编程背景即可创建自动化流程(如模拟滚动、点击、翻页),并支持海量预设模板,大幅降低了基础采集脚本的开发成本。
-
指纹与 IP 的匹配:能够根据所使用的代理 IP 自动匹配对应的时区、经纬度、系统语言以及 WebRTC 信息,确保 IP 归属地与浏览器内部参数高度一致。
最适合:大规模高并发采集(如社交媒体舆情监控、跨境电商比价)以及 AI Agent 自动化(为智能体提供稳定、可持续的页面操作窗口)。
我需要使用反检测浏览器来进行数据采集吗?
你可以对照以下三个标准,如果符合其中之一,建议使用:
1. 目标网站的反爬等级较高
现在的头部网站(如亚马逊、Facebook、Google、Shopee 等)不再只检查你的 IP 地址。它们会通过 JavaScript 脚本探测你的浏览器指纹,包括:
-
硬件特征: Canvas(绘图能力)、WebGL(显卡特征)、Audio(音频上下文)。
-
软件环境: 浏览器字体、系统语言、时区、WebRTC 等。
-
自动化特征: 是否存在
navigator.webdriver标志位。 如果你的脚本频繁触发验证码或被重定向到登录页,说明你的环境已被识别。
2. 需要多账号或多身份并发采集
如果你需要模拟不同地区、不同用户的访问行为(例如比价系统、广告效果监测),普通的浏览器无法在同一台设备上彻底隔离 Cookie 和指纹。一旦其中一个环境被封,其他环境极易发生“连坐”封禁。
3. 需要模拟真实的特定设备
有些数据仅在特定的浏览器版本下展示。反检测浏览器可以一键切换成上千种不同的设备环境,而无需购买大量实体设备。
AdsPower的反检测能力
在众多的工具中,AdsPower 针对数据采集场景提供了深度定制化的反检测能力:
1. 内核级的指纹掩饰(更难被识别)
AdsPower 深度优化了浏览器内核。它不仅能修改 UA(User Agent),还能在底层对 Canvas、WebGL、WebGPU、声音、字体 等 50 多个指纹参数进行去特征化处理,使采集行为看起来像来自不同的真实物理设备。
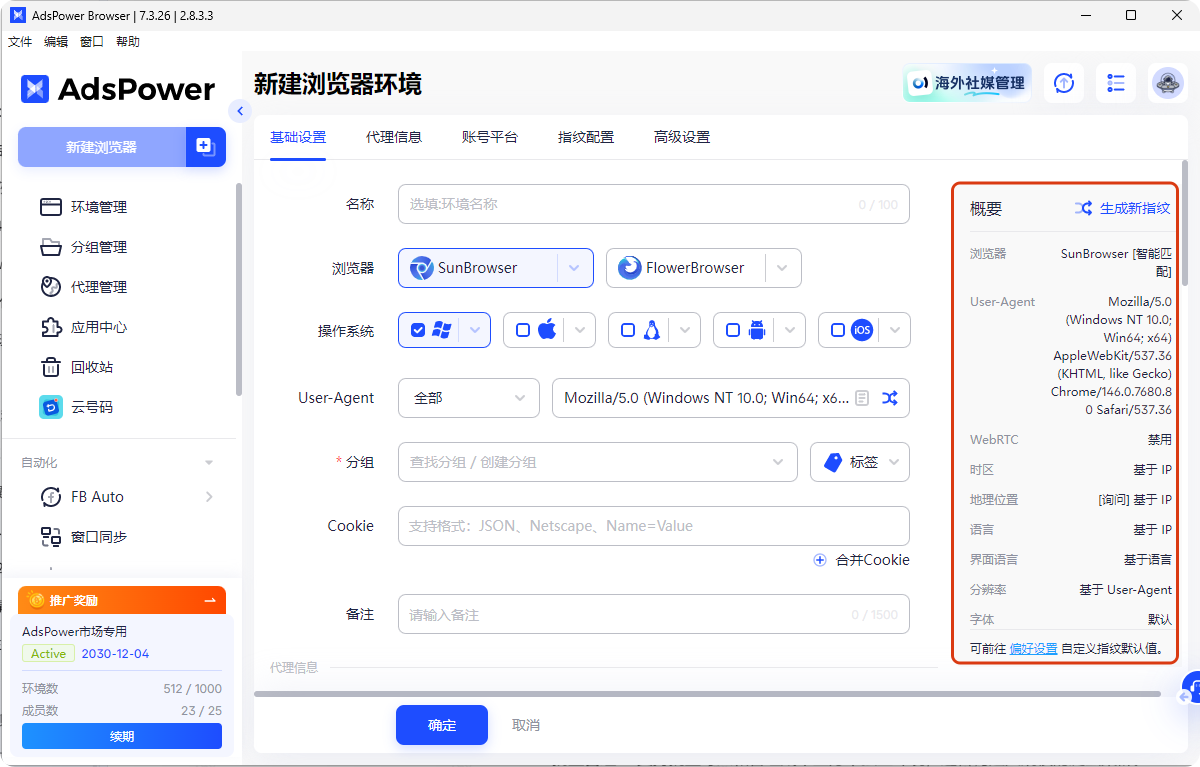
2. 环境隔离与“指纹-IP”高度匹配
-
物理级隔离:每个浏览器配置文件的 Cookie、缓存和本地存储(LocalStorage)都是完全独立的,确保不同采集任务之间零关联。
-
地理一致性:当你为采集环境配置代理 IP 时,AdsPower 会自动根据 IP 调整浏览器的时区、经纬度、系统语言。例如,使用纽约的 IP 时,浏览器内部的时区会自动变为 EST,避免因“IP 与系统环境不符”被目标网站拦截。
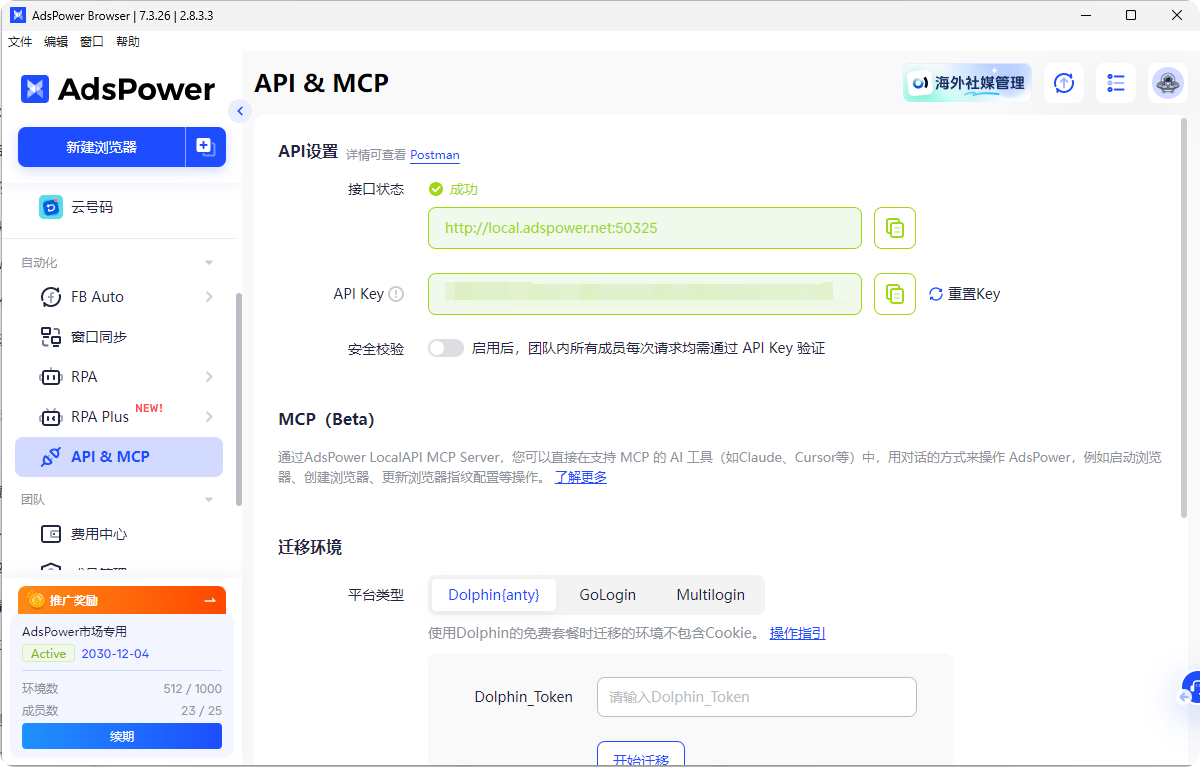
3. 高效的自动化对接
AdsPower 提供了成熟的 Local API。你可以通过代码控制环境的创建、启动和关闭,并无缝对接 Playwright、Puppeteer 和 Selenium。
启动浏览器后,你可以直接获取远程调试地址,像操作原生浏览器一样操作 AdsPower 里的高模拟环境。
4. 解决“放量不稳”的资源调度
-
按需启动:通过 API 调度,你可以实现任务跑完即释放环境,极大地优化了采集服务器的 CPU 和内存占用,解决了传统浏览器多开时资源耗尽的问题。
-
批量管理: 支持批量导入和管理成千上万个独立环境,适合构建大规模的爬虫集群。
5. 内置 RPA 机器人
如果你不想编写复杂的脚本,AdsPower 内置了 RPA 工具。通过拖拽即可实现自动点击、模拟滚动、翻页等模仿人类真实操作的行为,这种“类人化”的操作本身就是一种极强的反检测手段。
常见问题解答
什么是数据采集浏览器?
数据采集浏览器是一个实用的术语,指的是任何能够让你像真实用户一样加载现代网页并可靠地提取数据的工具——无论是网页抓取浏览器库、托管浏览器、托管抓取 API,还是用于创建干净配置文件的反检测浏览器。
无头浏览器进行网页抓取仍然可行吗?
是的,但这取决于目标。无头浏览器速度更快、成本更低,但更容易被检测到。对于高阻力目标,团队有时会切换到有头浏览器/有头执行方式。
何时应该选择 Playwright 而不是 Puppeteer?
如果需要跨浏览器兼容性以及一个专为应对现代网络不稳定性而构建的框架,Playwright 通常是首选。如果你完全依赖 Node.js 并且想要类似 DevTools 的控制界面,Puppeteer 则非常强大。

人们还读过
- AdsPower 新手零门槛环境配置教程,看完你也能快速创建安全、稳定的浏览器环境

AdsPower 新手零门槛环境配置教程,看完你也能快速创建安全、稳定的浏览器环境
AdsPower 环境配置全流程指南,新手零门槛入门,快速创建安全稳定的指纹浏览器环境。
- 如何安全批量注册Tinder账号?避免封号技巧

如何安全批量注册Tinder账号?避免封号技巧
了解 Tinder 账号为什么会被封、如何合规创建和维护账号、误封后如何申诉,以及在正规多账号工作流中如何用 AdsPower 做环境隔离和团队管理。
- 从 0 开始安全稳定用上官方 Claude Code:完整指南

从 0 开始安全稳定用上官方 Claude Code:完整指南
本文作者「劳伦斯」,总结出一套稳定使用Claude的防封经验。内容涵盖账号如何从0开始注册、IP一致性检测、指纹浏览器设置与订阅claude。由 AdsPower 用户原创投稿分享。
- 海外直播平台盘点 | 2026十个国外最受欢迎的直播平台

海外直播平台盘点 | 2026十个国外最受欢迎的直播平台
026海外直播平台盘点,详细介绍YouTube Live、Twitch、TikTok LIVE、Instagram Live、Facebook Live、Kick、BIGO LIVE、17LIVE、Shopee Live、Naver CHZZK,并讲解多账号运营如何用AdsPower指纹浏览器提升账
- Twitter/X账号被冻结如何快速解封?该如何避免?2026养号全攻略

Twitter/X账号被冻结如何快速解封?该如何避免?2026养号全攻略
Twitter/X账号被冻结怎么办?本文整理 2026 年快速解封步骤、常见冻结原因、养号防封技巧,并讲解如何借助 AdsPower 指纹浏览器降低多账号关联风险,提升网页版账号管理效率。

