
2025年网页抓取工具推荐:高效采集网页数据的策略
在大数据时代,网页抓取(Web Scraping) 已成为跨境电商、市场研究、SEO优化、学术研究等场景中的必备手段。通过网页抓取工具,我们可以高效地从目标网站获取价格、评论、产品信息、新闻等结构化数据,从而更快地做出业务决策。
不过,随着网站的反爬机制不断升级,想要稳定采集数据并不容易。选择合适的网页抓取工具,并结合一些实用的方法,才能在保证效率的同时降低被封风险。本文将带你了解2025年常用的10款网页抓取工具,并分享3个高效采集网页数据的方法,帮助你少走弯路。
1、BeautifulSoup
BeautifulSoup 是一个基于 Python 的网页解析库,专门用于从 HTML 和 XML 文档中提取数据。它不是一个独立的爬虫框架,而是网页抓取过程中解析与数据提取的重要工具。开发者通常会将它与 Requests 等网络请求库结合使用:先获取网页源代码,再利用 BeautifulSoup 解析并提取需要的信息。
主要作用
-
HTML/XML 解析:快速解析网页源码,生成树形结构,便于检索和操作。
-
数据提取:通过标签、属性或 CSS 选择器精准定位目标元素,比如商品标题、价格、新闻正文。
-
清洗数据:能去除网页中冗余的标签、广告或脚本,只保留有价值的数据。
-
辅助爬虫:在 Scrapy 等大型框架中,BeautifulSoup 也常作为辅助解析工具使用。
特点
-
易于上手:语法简单直观,非常适合 Python 初学者和数据分析新手。
-
容错率高:能够处理格式不规范的 HTML 文档,比起严格的解析器(如 lxml)更灵活。
-
多解析器支持:可以选择 Python 自带的
html.parser,或安装更高效的lxml。 -
社区活跃:文档齐全、教程丰富,遇到问题容易找到解决方案。
优点
-
学习成本低:几行代码就能实现基本的数据提取。
-
兼容性强:支持多种解析器,能处理大部分网页。
-
灵活性高:适合小规模、定制化的数据采集任务。
-
开源免费:完全免费,且不断更新维护。
缺点
-
效率一般:解析速度比不上 lxml 等更底层的解析器,不适合超大规模数据抓取。
-
功能单一:仅负责解析与提取,无法独立完成请求、并发、存储等完整爬虫流程。
-
对动态网页支持不足:无法直接处理由 JavaScript 渲染的内容,需要配合 Selenium、Playwright 等工具。
定价
BeautifulSoup 是完全免费的开源项目,基于 MIT 协议发布。用户可以自由使用、修改和分发,无需担心授权费用,非常适合个人开发者、学生和中小型团队。
2、Scrapy
Scrapy 是一个基于 Python 的开源网页抓取框架,被广泛应用于数据采集、信息抽取和网络爬虫项目。与 BeautifulSoup 不同,Scrapy 不仅仅是一个解析库,而是一个功能完整的爬虫框架,涵盖了请求调度、数据解析、去重机制和数据存储等完整流程。它适合需要高效、大规模采集数据的场景,比如电商商品信息采集、舆情监控和搜索引擎数据抓取。
主要作用
-
大规模网页抓取:能够高效发送并处理上千个请求,适合批量采集数据。
-
数据解析与抽取:通过 XPath、CSS 选择器或正则表达式精确提取网页元素。
-
请求调度与去重:框架内置调度器,可避免重复抓取,提高效率。
-
数据存储:采集的数据可直接导出为 JSON、CSV、XML,或写入数据库。
-
中间件扩展:支持代理池、请求头伪装、Cookies 管理等反爬措施。
特点
-
框架完整:内置请求调度、数据提取、存储、日志等功能。
-
高效并发:基于 Twisted 异步网络框架,抓取速度快,适合大规模数据采集。
-
可扩展性强:支持自定义中间件和管道,可以灵活应对不同网站的反爬机制。
-
社区活跃:作为最流行的 Python 爬虫框架之一,资料丰富,插件生态完善。
优点
-
高性能:异步并发机制保证了在处理成千上万网页时依然高效。
-
一站式解决方案:无需额外整合请求库或存储库,框架自带常用功能。
-
灵活可定制:可根据项目需求定制爬虫逻辑、代理策略、数据清洗和存储。
-
企业级应用适配:非常适合需要长期稳定运行的大型爬虫项目。
缺点
-
学习曲线较陡:相比 BeautifulSoup,Scrapy 的框架化思维和配置更复杂,新手需要一定学习成本。
-
开发周期较长:适合长期项目,不太适合临时性、小规模的数据采集。
-
对动态渲染支持不足:对于 JavaScript 动态加载的网页,仍需借助 Selenium、Playwright 等工具。
定价
Scrapy 完全免费、开源,基于 BSD 协议发布。用户可以自由使用、修改和扩展。Scrapy 背后的公司 Scrapinghub(现称 Zyte) 提供商业化服务,包括 Scrapy Cloud(云端爬虫托管)、Crawlera(智能代理)等,这些属于付费产品,但 Scrapy 框架本身没有使用成本。
3、Octoparse
Octoparse(八爪鱼采集器) 是国内的一款可视化网页数据抓取工具,面向全球市场。与需要编程的 Scrapy、BeautifulSoup 不同,Octoparse 主打零代码操作,用户只需通过“所见即所得”的点击操作,就能建立爬虫任务,适合非技术背景的用户。
它内置了浏览器和抓取引擎,可以模拟人工操作网页,完成数据采集,并支持导出到 Excel、CSV、数据库,甚至直接推送到云端 API。
主要作用
-
可视化建模:通过点击网页元素,生成采集规则,无需写代码。
-
动态网页抓取:内置浏览器能处理 JavaScript 渲染页面、下拉加载、翻页等复杂场景。
-
批量数据采集:可同时运行多个任务,适合大规模数据采集。
-
云端采集:支持把采集任务放到云端服务器运行,减少本地资源占用。
-
自动导出与集成:数据可导出为 Excel、CSV、JSON,也能对接数据库或 API。
特点
-
零代码上手:为没有编程经验的用户设计,操作界面直观。
-
跨平台支持:提供 Windows、Mac 客户端和网页版。
-
反爬机制应对:内置 IP 代理池、验证码识别等功能。
-
任务模板丰富:自带常见网站(如亚马逊、eBay、知乎)的抓取模板。
优点
-
用户友好:拖拽和点击操作即可完成规则设置。
-
功能全面:支持动态渲染、定时任务、代理 IP 等高级功能。
-
适合企业应用:云端采集和 API 对接方便团队协作和自动化。
-
无需开发成本:非技术人员也能快速启动数据采集项目。
缺点
-
学习门槛依然存在:虽然零代码,但复杂规则仍需要时间理解。
-
灵活性不如代码工具:对一些非常规网页结构,配置可能受限。
-
依赖软件生态:与开源框架相比,自由度有限。
-
价格较高:相比免费工具,Octoparse 的付费版本成本较大。
定价
Octoparse 提供免费版和付费版:
-
免费版:功能有限,适合个人测试或小规模抓取。
-
标准版:月费约 $69,支持更多任务数量、云端运行、IP代理。
-
专业版:月费约 $249,面向企业,支持更强大的并发和高级功能。
-
定制化服务:针对大企业提供专属方案。
4、ParseHub
ParseHub 是一款面向全球用户的可视化网页抓取工具,专注于零代码抓取和自动化数据采集。用户无需编程即可通过点击和选择网页元素来生成抓取规则,ParseHub 会自动分析网页结构,支持处理静态页面和动态渲染页面(包括 JavaScript、AJAX 内容)。
ParseHub 同样提供云端任务运行和 API 输出,适合个人用户、数据分析师和企业进行高效网页数据采集。
主要作用
-
可视化抓取:通过图形界面选择元素、设置翻页、循环和条件逻辑。
-
动态网页支持:可抓取 AJAX、下拉加载、点击触发的内容。
-
多任务运行:本地或云端执行任务,可同时抓取多个网页。
-
数据导出:支持导出为 CSV、Excel、JSON,或通过 API 对接应用。
-
自动化调度:可以设置定时抓取,实现数据定期更新。
特点
-
零代码操作:用户无需编写脚本,通过可视化界面即可完成复杂抓取。
-
跨平台支持:提供 Windows、Mac 及云端服务,无需安装复杂环境。
-
高级数据抽取:支持正则表达式、条件判断、循环和多级导航。
-
云端和本地双模式:任务可在本地运行,也可托管在云端,实现自动化。
优点
-
操作简单:适合没有编程经验的个人和团队使用。
-
功能全面:可处理静态和动态网页,支持复杂抓取逻辑。
-
自动化强:支持定时任务和云端运行,减少人工操作。
-
国际化支持:针对全球网站优化,适合多语言抓取需求。
缺点
-
免费版功能受限:免费版只能抓取少量网页和任务,云端功能有限。
-
复杂逻辑受限:对于一些非常规网页结构或极度动态化页面,灵活性不如 Scrapy。
-
价格较高:付费版针对企业功能强大,但对个人用户成本较高。
-
依赖网络稳定性:云端抓取受网络影响较大,若网页频繁变化可能需要重新配置任务。
定价
ParseHub 也提供免费版和付费版:
-
免费版:支持最多 200 页抓取,有限的云端任务和更新频率。
-
标准版:约 $189/月,支持更多页面抓取、云端任务和 API 输出。
-
专业版:约 $599/月起,适合大规模、定制化抓取和团队协作。
5、Selenium
Selenium 是一个广泛使用的浏览器自动化工具,最初用于 Web 应用的测试,但由于其强大的页面控制能力,也被广泛应用于网页抓取。Selenium 可以通过程序控制浏览器完成页面加载、点击、滚动、表单填写等操作,因此非常适合抓取 JavaScript 动态渲染的网页内容。
Selenium 支持多种浏览器(Chrome、Firefox、Edge、Safari 等)以及多种编程语言(Python、Java、C# 等),开发者可以结合它模拟真实用户行为,实现复杂网页抓取。
主要作用
-
动态网页抓取:处理 AJAX、下拉加载、点击事件等动态生成的数据。
-
浏览器自动化:模拟人工操作,如点击按钮、输入搜索内容、分页操作。
-
数据采集:结合解析库(如 BeautifulSoup 或 lxml)提取所需数据。
-
自动化测试:原本用途之一,可同时进行测试与数据抓取。
-
防反爬对策:模拟真实用户浏览行为,降低被简单反爬机制拦截的概率。
特点
-
浏览器级操作:可真实模拟用户操作,抓取 JS 渲染内容。
-
跨语言和跨平台:支持 Python、Java、C# 等多种语言,兼容 Windows、Mac、Linux。
-
可扩展性强:可与 BeautifulSoup、Pandas、数据库等结合,实现完整的数据采集和存储流程。
-
社区活跃:拥有大量教程、插件和实践案例,适合不同水平开发者。
优点
-
动态抓取能力强:几乎可以抓取任何页面,无论是静态还是 JS 动态渲染。
-
真实浏览器模拟:可以完全模拟人类操作,降低被封或被识别为爬虫的风险。
-
灵活性高:可执行任意操作,包括点击、滚动、拖拽、键盘输入等。
-
开源免费:完全免费使用,并有活跃的社区支持。
缺点
-
抓取速度慢:相比 Requests + BeautifulSoup 或 Scrapy,Selenium 需要启动浏览器,速度较慢。
-
资源消耗大:需要占用较多 CPU 和内存,尤其是大量并发抓取时。
-
部署复杂:需要配置浏览器驱动(如 ChromeDriver),本地部署或服务器运行配置稍复杂。
-
不适合大规模爬虫:除非结合分布式系统,否则超大规模抓取不够高效。
定价
Selenium 也是开源免费软件,基于 Apache 2.0 协议发布。用户可以自由使用、修改和分发,无需支付费用。
6、Playwright
Playwright 是由 Microsoft 开发的一款 现代浏览器自动化框架,类似于 Selenium,但在性能、稳定性和功能上更强大。它不仅支持主流浏览器(Chrome、Firefox、WebKit),还能在无头模式下运行,高效完成网页抓取任务。Playwright 特别适合处理复杂动态网页和 SPA(单页应用),能够应对大量 JavaScript 渲染和异步加载的场景。
Playwright 支持多种编程语言(Python、JavaScript/TypeScript、C#、Java),并提供高级 API,使开发者能够灵活控制浏览器操作、模拟用户行为和抓取数据。

主要作用
-
动态网页抓取:可抓取 JavaScript 渲染、下拉加载、滚动分页等内容。
-
浏览器自动化:模拟点击、输入、拖拽、表单提交等操作。
-
跨浏览器抓取:一次编写代码即可在 Chromium、Firefox、WebKit 三大浏览器运行。
-
数据提取:结合解析库(如 BeautifulSoup、lxml)或 Playwright 内置选择器提取数据。
-
防反爬对策:可模拟真实用户行为,降低被反爬机制识别的风险。
特点
-
跨浏览器支持强:支持 Chromium、Firefox、WebKit,确保抓取效果一致。
-
高性能:相比 Selenium,启动更快、占用资源更少,支持无头模式。
-
自动等待机制:内置智能等待(auto-waiting),无需手动 sleep,提高抓取稳定性。
-
多语言支持:Python、JavaScript/TypeScript、Java、C#,适合不同开发者。
-
丰富 API:支持截图、PDF 导出、网络拦截、模拟地理位置、网络状态等操作。
优点
-
抓取动态网页能力强:适合现代复杂网页和单页应用。
-
性能优越:比 Selenium 更快,占用资源更少。
-
稳定性高:智能等待机制减少因页面加载延迟导致的抓取失败。
-
开源免费:完全免费使用,适合个人和企业项目。
-
灵活性高:支持高级模拟操作,如地理位置、用户行为和网络条件。
缺点
-
学习成本:相比 Selenium,Playwright API 更丰富,需要一定学习时间。
-
依赖开发能力:需编写代码,不适合零代码用户。
-
部署复杂:需要配置浏览器环境和依赖库,本地或服务器部署都需注意兼容性。
-
社区相对较新:虽然发展迅速,但相对于 Selenium,历史文档和插件生态略少。
定价
Playwright 完全免费开源,基于 Apache 2.0 协议发布,可自由使用、修改和分发。
7、Diffbot
Diffbot 是一款基于人工智能和机器学习的网页抓取与结构化数据提取服务,面向企业用户。与传统爬虫不同,Diffbot 不依赖固定的抓取规则,而是通过 AI 自动理解网页结构,将网页内容(如文章、产品、评论等)转化为结构化数据。
Diffbot 提供 API 接口,开发者无需自己写复杂爬虫,就能获取干净、结构化的数据,非常适合大规模数据采集、竞争分析、商业智能和数据驱动决策。

主要作用
-
结构化数据提取:自动识别网页内容类型(文章、产品、讨论、列表等),生成结构化 JSON。
-
知识图谱构建:可以抓取大量网页并建立企业或行业知识图谱。
-
大规模数据采集:无需手动解析 HTML,即可批量获取高质量数据。
-
API 数据服务:通过 REST API 获取实时数据,适合与 BI 系统、数据库或分析工具对接。
-
自动识别网页结构变化:AI 模型能应对网页结构变动,减少抓取规则维护成本。
特点
-
AI 自动解析:不依赖手写 XPath 或 CSS 选择器,智能识别网页内容。
-
实时 API:通过 Diffbot API 即可快速获取最新数据,无需部署本地爬虫。
-
支持多种内容类型:文章、产品、讨论、评论、列表等,几乎覆盖所有网页信息。
-
高稳定性:企业级服务,适合长期、稳定的数据抓取任务。
-
兼容性强:支持 JSON、CSV 等多种数据输出格式。
优点
-
无需写代码:通过 API 获取结构化数据,减少开发成本。
-
自动适应网页变化:AI 模型自动处理网页结构变化,降低维护难度。
-
数据质量高:提取结果清晰、准确,无需再进行额外清洗。
-
企业级稳定性:适合长期项目和大规模数据采集。
缺点
-
价格昂贵:针对企业用户,按 API 调用次数计费,对个人和小型团队不够友好。
-
灵活性有限:不适合需要自定义逻辑或复杂操作的抓取场景。
-
依赖网络和服务稳定性:需连接 Diffbot 云端,网络或服务中断会影响抓取。
-
学习曲线:虽然无需写爬虫代码,但仍需理解 API 调用和数据结构。
定价
Diffbot 为商业化 SaaS 服务,提供多种订阅计划:
-
免费计划:每月 10,000 Credits。
-
启动计划:$299/月,每月 250,000 Credits。
-
高级计划:$899/月,每月 1,000,000 Credits。
-
企业计划:定制价格和信用额度,支持 100 个以上活跃爬虫任务,并提供专属客户经理和高级支持。
8、WebHarvy
WebHarvy 是一款面向非技术用户的可视化网页抓取工具,由印度开发团队推出。它无需编程,通过图形界面即可轻松抓取网页数据。WebHarvy 内置浏览器和自动识别技术,可以快速提取网页中的文本、图像、URL、表格等信息,并支持导出为多种格式,如 Excel、CSV、XML 或数据库。
主要作用
-
可视化抓取:通过点击选择网页元素,自动生成抓取规则,无需编写代码。
-
自动识别数据模式:内置智能模式识别,能自动发现列表、表格和分页结构。
-
动态网页支持:可抓取 AJAX 或 JavaScript 渲染的网页内容。
-
批量抓取与导出:支持多任务并行抓取,数据可导出为 Excel、CSV、XML 或数据库。
-
定时任务:可设置定时抓取,实现数据定期更新。
特点
-
零代码操作:用户通过可视化界面即可完成抓取配置。
-
智能数据识别:自动识别网页中的重复数据模式和分页内容。
-
批量任务支持:可以同时运行多个抓取任务,提高效率。
-
多格式导出:支持 Excel、CSV、XML、SQL 数据库等多种导出方式。
优点
-
操作简单:无需编程,适合非技术人员。
-
数据提取灵活:支持文本、图片、URL、表格等多种类型。
-
自动化高:支持分页抓取、定时任务和批量操作。
-
节省开发成本:快速建立抓取任务,减少维护工作。
缺点
-
功能受限:对于极其复杂的动态网页或需要自定义逻辑的抓取场景,灵活性有限。
-
速度相对一般:相比 Scrapy 或 Playwright,高速并发抓取能力较弱。
-
商业化软件:需要付费才能解锁全部功能。
-
对开发者不友好:缺少代码接口,不适合想完全定制化抓取逻辑的技术用户。
定价
WebHarvy 提供一次性付费授权,无需续订,也提供企业定制方案:
-
单用户授权:约 $129,一次性购买,适合个人用户,包含 1 年免费更新和技术支持,终身使用授权。
-
多用户授权(2~4 User License):约 $219~$359,可覆盖 2~4 台电脑,包含 1 年免费更新和技术支持,终身使用授权。
-
企业授权(Site License):约 $699,可用于公司或组织的无限用户和电脑,包含 1 年免费更新和技术支持,终身使用授权。
在认识了这些网页抓取工具后,真正考验采集效率的,是方法与策略。光有工具还不够,如果不懂得如何科学规划抓取流程、管理访问频率、处理动态网页或应对反爬机制,抓取的数据可能不完整甚至被封号。
要想高效采集网页数据,需要从多个方面入手。接下来,我们将分享 3 大最佳实践,帮助你在提升效率的同时,保证数据采集的稳定性和安全性。
如何高效采集网页数据?
1、合理选择抓取方式
不同网站的数据加载机制差异很大,如果使用错误的方法,不仅抓取效率低,还可能获取不到完整数据,甚至增加被封的风险。
静态抓取
静态抓取是指直接发送 HTTP 请求,获取网页的源代码,然后通过解析 HTML 提取所需信息。其特点包括:
-
高效率:无需加载页面中的 JavaScript 或其他动态内容,速度快,适合批量采集。
-
易于实现:常用工具包括 BeautifulSoup 等,只需解析源代码即可提取数据。
-
适用场景:新闻网站、博客、论坛帖子、商品列表页等静态内容丰富的网页。
例如,你想抓取一个新闻网站的文章标题、发布时间和作者信息,只要网页内容直接写在 HTML 中,使用静态抓取即可轻松获取,而且处理速度快,占用资源少。
动态抓取
随着现代网站越来越多使用 JavaScript 动态渲染内容,静态抓取往往无法获取完整数据。这时,就需要动态抓取技术:
-
原理:通过模拟真实浏览器环境,加载网页的 JavaScript 和异步请求,获取完整渲染后的 DOM。
-
常用工具:Selenium、Playwright、Puppeteer 等,可以模拟点击、滚动、下拉分页等用户行为。
-
适用场景:电商平台商品详情页、社交媒体动态、单页应用(SPA)、需要登录才能访问的数据。
例如,在抓取电商平台的商品价格和库存信息时,页面通常通过 Ajax 请求动态加载,如果直接请求源代码,你可能只能拿到空白模板。此时,Selenium 或 Playwright 可以完整渲染页面,确保数据获取准确。
2、使用代理 IP 与 IP 轮换
在网页抓取过程中,IP 是访问网站的“身份标识”。许多网站会限制单一 IP 的访问频率,尤其是针对频繁请求的数据抓取,如果不加控制,很容易触发风控规则,导致 IP 被封,抓取任务中断。为了保证数据采集的稳定性和高效性,合理使用代理 IP 与轮换策略非常关键。
使用代理 IP
代理 IP 可以帮助你隐藏真实 IP,模拟来自不同地区或不同用户的访问。常见的代理类型包括:
-
住宅 IP:由真实用户提供的 IP,通常更不容易被网站识别为爬虫。
-
高匿名代理:隐藏真实 IP,网站无法检测到请求来源,适合需要高安全性的抓取场景。
通过代理访问,可以有效降低单一 IP 被封的风险,同时在抓取区域限制内容时(例如仅允许特定国家访问),代理 IP 也能解决地理限制问题。
建立动态代理池
为了应对大量请求,可以建立动态代理池:
-
定期轮换 IP:每隔一定请求数量或时间,就切换新的 IP,分散访问压力。
-
智能选择:根据抓取任务类型,优先选择响应速度快、稳定性高的代理。
-
避免重复使用同一 IP:连续使用同一 IP 可能触发风控机制或验证码。
动态代理池可以显著降低被封 IP 的概率,保证长时间抓取任务的连续性和效率。
结合抓取工具自动切换
现代抓取工具(如 Scrapy、Octoparse 等)通常支持代理自动切换功能:
-
每次请求可随机选择代理 IP,模拟多用户访问行为。
-
可设置重试机制,当某个代理请求失败时自动切换到其他代理。
-
与定时任务或分布式抓取结合使用,进一步提升抓取效率。
3、模拟真实用户环境
在现代网站防护机制中,IP 并不是唯一的检测手段。许多网站会通过浏览器指纹来识别访问者,包括操作系统类型、浏览器版本、时区、字体、WebGL 渲染信息、Cookies、LocalStorage 等数据。即使更换了代理 IP,如果多个请求的浏览器指纹高度相似,仍然可能被网站识别为爬虫或异常行为,从而触发封禁或验证码。
指纹浏览器的核心作用
指纹浏览器如 AdsPower 就专门用于模拟真实用户环境,它能够为每个抓取任务生成独立的浏览器环境,从而避免多账号、多任务之间的指纹关联。例如,你需要从电商平台抓取商品信息,如果只用爬虫工具,频繁请求可能很快触发风控;使用指纹浏览器后,每个抓取任务都像是不同的真实用户访问,即便频繁访问,也不容易被封号或限制。
AdsPower 的主要优势包括:
-
独立环境生成:每个任务拥有唯一的操作系统、浏览器指纹、Cookies 和插件配置。不同任务之间完全隔离,降低被检测的概率。
-
结合代理 IP 使用:与动态代理池结合,每次请求不仅有不同的 IP,还拥有独特的指纹信息。
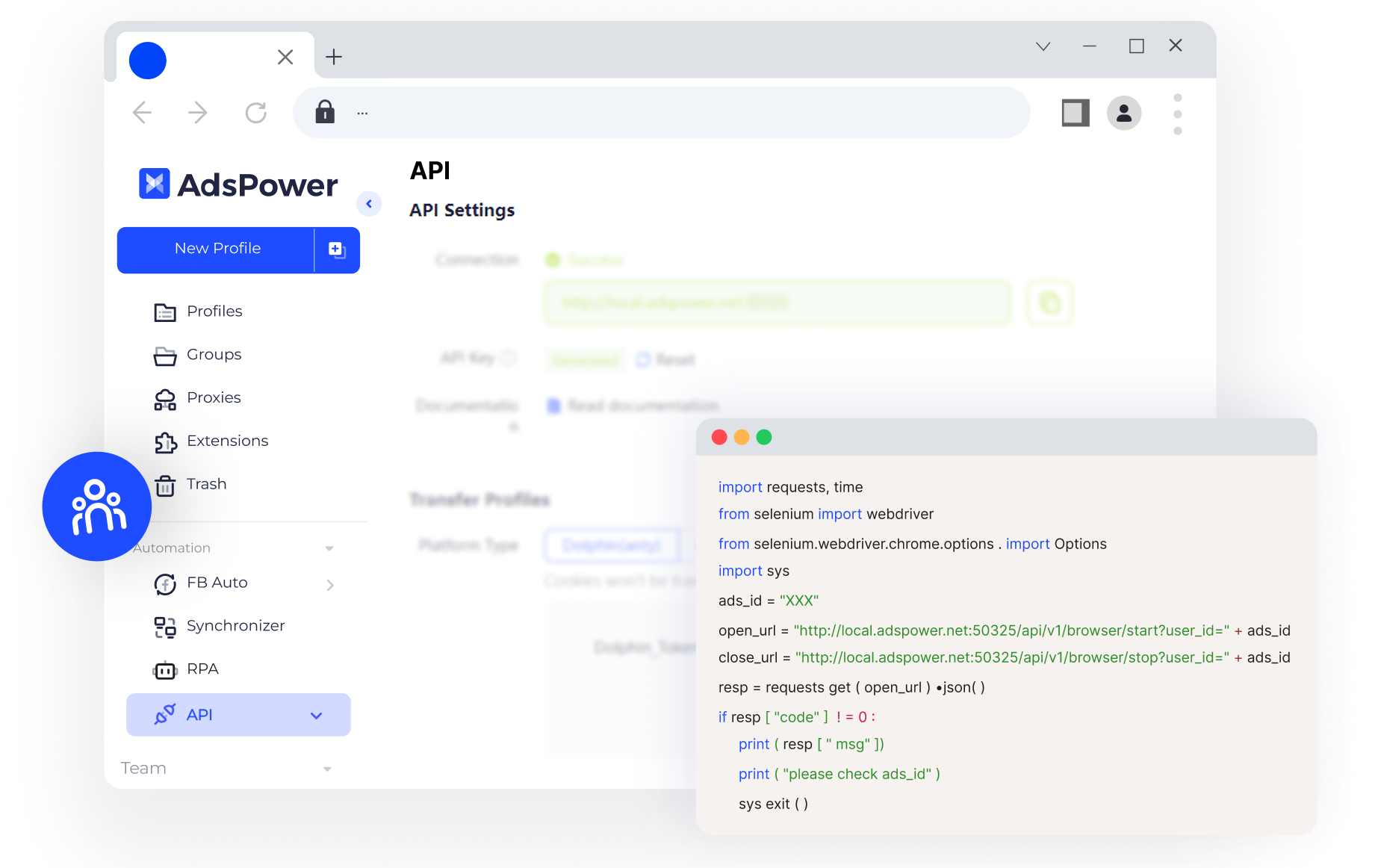
-
自动化与批量管理:提供 API 接口,可以与 Selenium、Playwright、Octoparse 等爬虫工具无缝对接。支持批量创建、管理和切换指纹环境,适合大规模数据抓取任务。
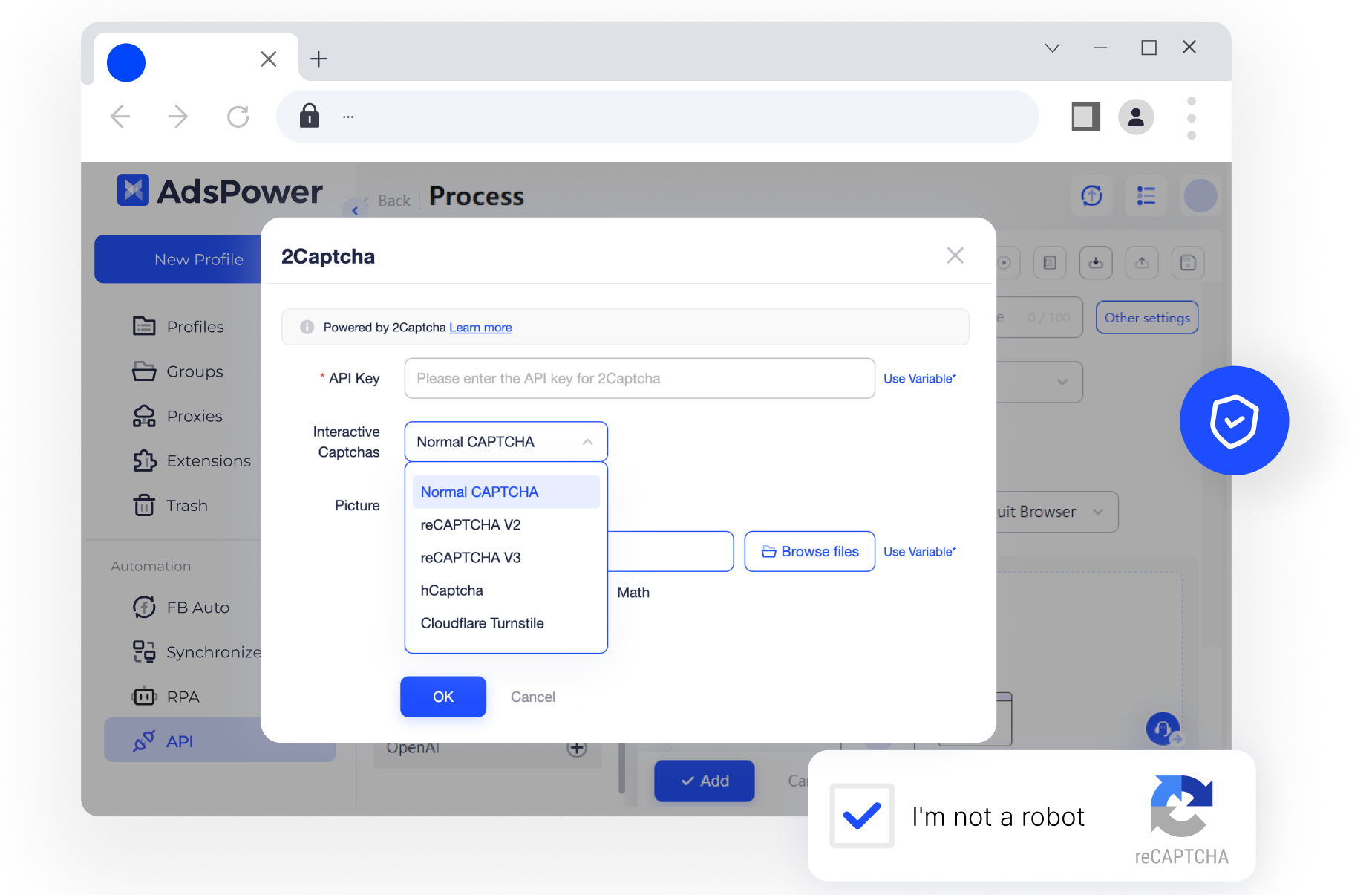
除此之外, AdsPower RPA 集成「2Captcha」,实现了“自动人机验证”,轻松帮助用户破解验证码。
通过指纹浏览器,抓取工具与代理 IP 相结合,能够在保证数据完整性的同时,大幅降低被识别为爬虫的风险,使网页数据采集既高效又安全。
结语
在 2025 年,网页抓取依旧是数据驱动业务的重要手段。
-
如果你是开发者,可以选择 Scrapy、BeautifulSoup 等。
-
如果你是非技术人员,可以考虑 Octoparse、ParseHub、WebHarvy。
-
企业级需求则推荐 Diffbot。
同时,在面对反爬机制时,抓取方式、、代理IP、指纹浏览器是实现高效采集的三大关键。尤其是指纹浏览器,能帮助你在账号隔离、防封方面获得巨大优势,是大规模网页抓取项目的效率工具。
借助本文推荐的工具与方法,相信你能够更稳定、更高效地采集所需的网页数据。


人们还读过
- Bing广告指南:必应广告账号封禁原因及降低封号风险的方法

Bing广告指南:必应广告账号封禁原因及降低封号风险的方法
了解必应广告(Bing Ads)账号封禁的常见原因,以及如何有效降低被封号的风险。本文将深入分析违规行为、账户设置及广告内容的合规性,提供实用的建议和技巧,帮助您安全推广,优化广告投放策略。
- 2026 最佳联盟营销平台推荐:10 大 Affiliate Network 盘点

2026 最佳联盟营销平台推荐:10 大 Affiliate Network 盘点
不知道该选择哪个Affiliate Network?本文将盘点2026年10大最值得推荐的联盟营销平台,对比Awin、Amazon Associates、ClickBank等平台的特点、佣金模式和适用场景,并分享多平台运营与账号管理建议,帮助联盟客找到适合自己的推广平台,提高联盟营销收益。
- 为什么 ChatGPT Pro 会突然变成 Mini?原因分析及解决方法

为什么 ChatGPT Pro 会突然变成 Mini?原因分析及解决方法
为什么 ChatGPT Pro 会突然变成 Mini?本文分析网络IP、账号状态、模型限制、系统负载等原因,并提供完整解决方法,帮助恢复 ChatGPT 正常体验,避免大模型降智影响 AI 使用。
- 使用Playwright被检测为机器人的原因及反检测方案

使用Playwright被检测为机器人的原因及反检测方案
使用 Playwright 进行浏览器自动化、数据采集或爬虫开发时,为什么容易被识别为机器人?本文深入解析 Playwright 被检测的常见原因、网站机器人检测机制以及浏览器指纹、代理 IP、用户行为等关键因素,并介绍 Playwright Stealth、AdsPower 指纹浏览器等主流反检测
- AdsPower 官方代理 IP 上线!端内直接买,一站配好环境

AdsPower 官方代理 IP 上线!端内直接买,一站配好环境
AdsPower 官方代理IP正式上线,无需切换平台即可完成代理IP购买、配置与管理,一站式搭建浏览器环境,提高账号管理效率。

