
网页自动化入门指南:一篇文章讲清浏览器自动化的核心原理与实现方式
你有没有想过:每天重复点网页、填表、登录账号、复制粘贴数据,真的非人来做不可吗?答案当然是否定的。这正是网页自动化存在的意义。
随着 AI、RPA 和智能办公的发展,大量重复性的网页操作正在被自动化程序替代。无论是电商运营、数据采集、广告投放,还是 AI Agent 执行任务,背后几乎都离不开浏览器自动化技术。
这篇文章将从基础概念、核心原理以及主流工具等方面,帮助你真正理解“网页自动化”到底是如何实现的。
什么是网页自动化?
网页自动化(Web Automation)指的是:通过程序自动完成网页中的操作流程。简单来说就是用程序代替人,在网页上完成操作。例如:
-
自动登录网站
-
自动填写表单
-
自动点击按钮
-
自动采集网页数据
-
自动上传内容
-
自动发布商品
-
自动管理社媒账号
网页自动化与人工操作最大的区别只有三个字:效率高。程序不会累、不犯困、不手抖。你点一百次按钮要十分钟,自动化可能十秒钟搞定。更重要的是,它可以7×24 小时工作。
网页自动化和浏览器自动化有什么区别?
很多初学者在接触网页自动化时,都会被这两个概念绕晕。网页自动化和浏览器自动化听起来很像,但并不完全等同。
网页自动化是一个更宽泛的概念。它指的是:
使用程序或工具,自动完成一切原本需要人在网页相关场景中手动完成的操作。
这里的“网页相关”,不一定非要真的打开一个浏览器窗口。例如:
-
通过 HTTP 请求直接获取网页数据
-
批量提交表单或接口请求
-
自动化登录、数据采集、内容同步
-
网络爬虫批量抓取信息
只要目标是“网页系统”,都可以归入网页自动化的范畴。
浏览器自动化则更具体,它是网页自动化的一种实现方式。
它的核心特点是:
程序直接控制真实浏览器(Chrome、Firefox、Edge 等)进行操作。
浏览器自动化会真正打开浏览器,完整加载页面,执行 JavaScript,并模拟真实用户的行为,例如:
-
鼠标点击、键盘输入
-
页面滚动、窗口切换
-
处理动态渲染内容
-
与 DOM、事件、JS 引擎交互
Selenium、Playwright、Puppeteer,以及各类浏览器自动化工具,本质上都属于浏览器自动化。
实际上,现代网页的绝大多数交互逻辑都发生在浏览器端。网页的渲染、JavaScript 的执行、用户事件的响应,乃至复杂的动态数据加载,都依赖于浏览器这一强大的“运行时环境”。
因此,要实现真正意义上的“网页自动化”,尤其是在处理复杂的、动态的、与用户交互密切的网页时,就必须深入到浏览器内部。通过模拟浏览器环境、理解其渲染机制、捕获和触发其事件,才能精准有效地自动化这些过程。
即使是那些不直接打开浏览器窗口的网页自动化(例如纯 HTTP 请求),其背后也往往是基于对浏览器行为的逆向分析——即了解浏览器在加载和操作页面时,会发出哪些请求、如何处理响应。
所以,虽然网页自动化概念更广,但浏览器自动化是当前实现复杂网页自动化最主流、最直接、也是最能体现其核心技术挑战的实现方式。
浏览器自动化的核心原理
浏览器自动化的本质,是通过某种方式向浏览器发送指令,让它“照做”。这些指令通常包括:打开 URL、查找元素、触发点击事件等。
DOM、事件与脚本注入
浏览器中的网页,本质是一个 DOM (Document Object Model) 树。你可以将其想象成一个网页的骨架,清晰地描述了所有元素(如标题、段落、按钮、输入框)及其层级关系。自动化工具的核心能力之一,就是能够“看懂”这棵 DOM 树,并精准地定位到你想要操作的每一个元素。
-
定位元素: 就像你在地图上找到具体地点一样,自动化工具可以通过元素的
ID、Name、Class Name、Tag Name、CSS Selector甚至XPath等多种方式,精确地“锁定”目标元素。 -
模拟用户行为: 一旦定位到元素,自动化工具就能模拟真实用户的操作:
-
点击:比如按下按钮、链接。
-
输入:在文本框中填写用户名、密码。
-
滚动:模拟用户滑动页面,加载更多内容。
-
-
事件与脚本注入:现代网页的动态性和交互性极强,很多功能依赖于 JavaScript 来实现。自动化工具不仅能模拟用户最直接的点击和输入,还能通过“脚本注入”的方式,直接在浏览器环境中执行 JavaScript 代码。这意味着:
-
我们可以直接调用页面上的 JavaScript 函数。
-
可以读取或修改页面的 JavaScript 变量。
-
可以触发更复杂的浏览器事件,这些事件可能是普通点击操作难以模拟的。
-
这种精准的操作能力,使得自动化能够胜任从简单的信息提取到复杂的业务流程模拟等各种任务。
常见的浏览器自动化架构
要实现上述的“控制”,就需要一套行之有效的“通信协议”和“执行框架”。当前主流的浏览器自动化架构主要有以下两种:
1、客户端脚本 + 浏览器驱动 (WebDriver)
工作流程:
你的自动化脚本(例如用 Python, Java, JavaScript 编写)作为“客户端”,通过调用 WebDriver 库(如 Selenium WebDriver)。WebDriver 库会将你的指令转换为一种标准的网络协议(WebDriver Protocol)。
这个协议会发送给一个叫做“WebDriver Server”(如 ChromeDriver, GeckoDriver)的独立程序。WebDriver Server 接收到指令后,会与真实的浏览器(如 Chrome, Firefox)进行通信,并驱动浏览器执行相应的操作。
最后,浏览器将操作结果(如元素是否找到,点击是否成功)反馈给 WebDriver Server,再经由 WebDriver 库返回给你的脚本。
优点:
-
标准化:WebDriver Protocol 是 W3C 标准,确保了跨浏览器(Chrome, Firefox, Edge, Safari)和跨语言(Python, Java, C#, JavaScript 等)的兼容性。
-
生态成熟:基于 WebDriver 的工具拥有庞大的社区支持和丰富的第三方库。
代表工具:Selenium。

2、直接通过浏览器提供的调试协议 (如CDP)
工作流程:
这种架构绕过了 WebDriver Server,直接利用浏览器开发者工具提供的底层通信接口(CDP 是 Chrome/Edge 的例子,Firefox 也有类似的协议)。
自动化工具(如 Puppeteer, Playwright)通过 WebSocket 等方式,直接与浏览器建立连接,并发送 CDP 指令。浏览器接收到指令后,能够执行非常底层的操作,例如网络请求的拦截与修改、页面内容的精细控制、性能监控等。
优点:
-
性能更高:由于省去了 WebDriver Server 的转换环节,通常速度更快。
-
功能更强大:CDP 提供了比 WebDriver 更丰富、更底层的能力,例如:
-
网络代理/劫持:拦截、修改或模拟网络请求(对网页抓取和测试非常有价值)。
-
Console 日志、Performance 记录:方便调试和分析。
-
更精细的 DOM 操作和事件模拟。
代表工具:Puppeteer, Playwright。
浏览器自动化面临的挑战与风险
反爬与反自动化机制
现代网站为了保护自身数据和用户体验,普遍部署了复杂的反爬虫和反自动化检测机制。这些机制如同自动化的“天敌”,让脚本的执行变得异常困难。
-
验证码 (CAPTCHA):最常见的障碍之一,用于区分人类用户和自动化程序。传统的图片验证码、滑块验证码,到如今更复杂的逻辑验证,都极大地增加了自动化识别的难度。尽管有 OCR 识别技术或打码平台,但其成本和成功率往往难以保证。
-
行为分析:网站会监测用户的鼠标移动轨迹、键盘输入速度、滚动行为、点击模式等。异常的、非人类的、机械式的操作模式很容易被检测出来,从而触发风控机制,如限制操作、强制验证,甚至封禁账号。
-
设备指纹 (Device Fingerprinting):网站可以通过分析用户的浏览器配置(如 UA、屏幕分辨率、字体、Canvas、WebGL 渲染特征、时区、语言等)来创建一个独一无二的“设备指纹”。即使清除 Cookie,只要设备指纹不变,网站就能“识别”出是同一个“访客”或“设备”。这使得普通浏览器在执行自动化操作时,很容易被网站关联并检测为异常。
-
JavaScript 混淆与动态加载:许多网站使用混淆后的 JavaScript 代码来隐藏逻辑,或者通过 AJAX 动态加载数据,这增加了自动化工具解析页面和触发行为的难度。
稳定性与维护成本
即使成功绕过了反自动化检测,自动化脚本的稳定性和维护成本也是一个不容忽视的问题。
-
网页结构变更:网站运营方会不断更新界面、调整布局、修改元素 ID 或类名。一旦网页结构发生变化,原本精准的元素定位器就会失效,导致脚本出错。这意味着每次网站更新后,都需要投入人力去检查和修改脚本,这是一项持续且耗时的维护工作。
-
浏览器与驱动更新:浏览器本身也在不断更新,新版本可能改变其内部接口或行为,导致旧的自动化工具或脚本出现兼容性问题。同时,与浏览器配套的 WebDriver 驱动也需要及时更新。
-
第三方库依赖:自动化脚本通常依赖多个第三方库,这些库的更新、冲突或弃用都会影响脚本的正常运行。
-
环境配置复杂性:自动化环境的搭建和维护本身也需要一定的技术门槛,特别是当需要模拟多种浏览器、操作系统或特定网络环境时。
面对上述挑战,特别是反爬与反自动化机制中的“设备指纹”和“账号关联”问题,以及保证脚本在复杂场景下的稳定性,浏览器指纹技术应运而生,并催生了AdsPower指纹浏览器这类专业工具。
传统浏览器在处理多账号或执行自动化任务时,极易被网站追踪和关联,从而触发风控。指纹浏览器通过模拟出一套独特的、可控的浏览器环境,让每个浏览器实例在网站眼中都像一个全新的、独立的访客。这不仅能有效规避账号关联和封禁风险,还能在一定程度上模拟真实用户的行为,从而绕过某些基于设备指纹的检测。AdsPower 指纹浏览器尤其在指纹模拟的全面性、可配置性以及与自动化操作的结合方面做得非常出色。
AdsPower 在浏览器自动化中的作用
提供安全隔离的浏览器环境
AdsPower 能够为每个浏览器环境创建一套独立且高度可定制的浏览器指纹,包括 UA、分辨率、字体、Canvas、WebGL、时区、语言等数十种参数,同时配置独立的代理 IP。这种隔离性和定制性使得自动化脚本在运行时,能够模拟出完全不同的浏览器环境,从而有效规避网站检测到的账号关联风险,提高多账号操作的成功率和安全性。
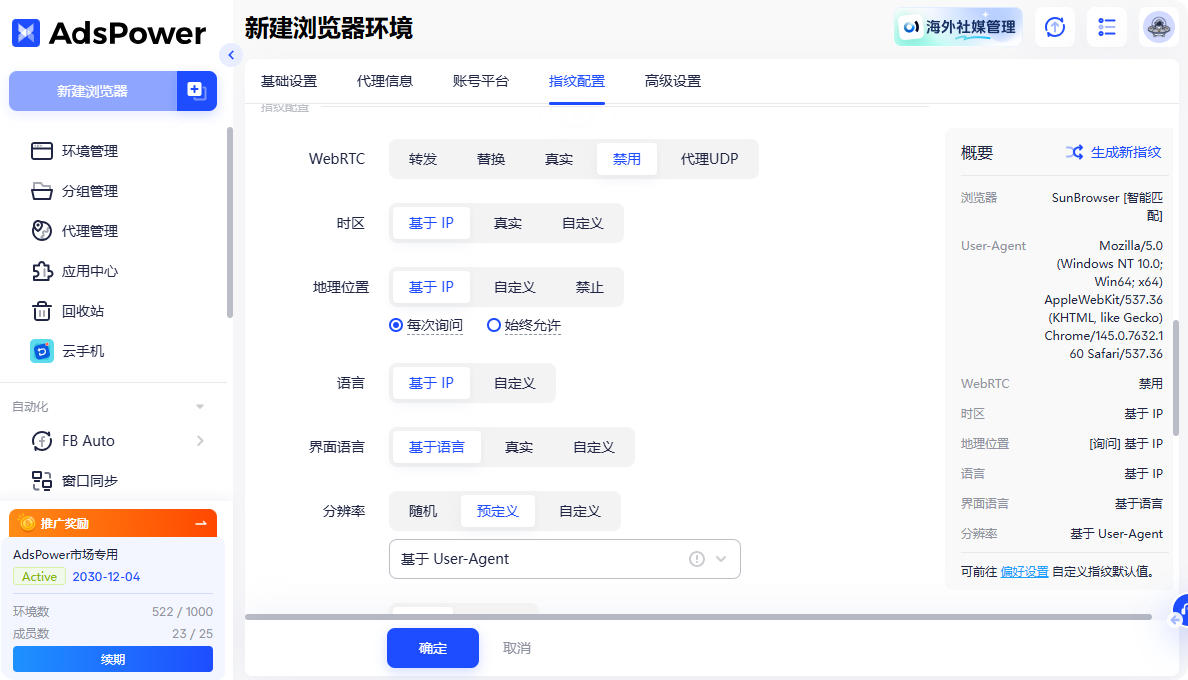
简化反爬机制的应对
通过模拟真实的浏览器环境,AdsPower 能在一定程度上规避网站基于设备指纹的检测。同时,结合其浏览器实例的隔离性,可以间接降低因操作异常而触发验证码或行为分析的概率。
支持主流自动化框架集成
通过本地 API 接口,开发者可以将 AdsPower 与 Selenium、Playwright、Puppeteer 等主流自动化框架深度集成,实现更加稳定、安全、可规模化的浏览器自动化系统。
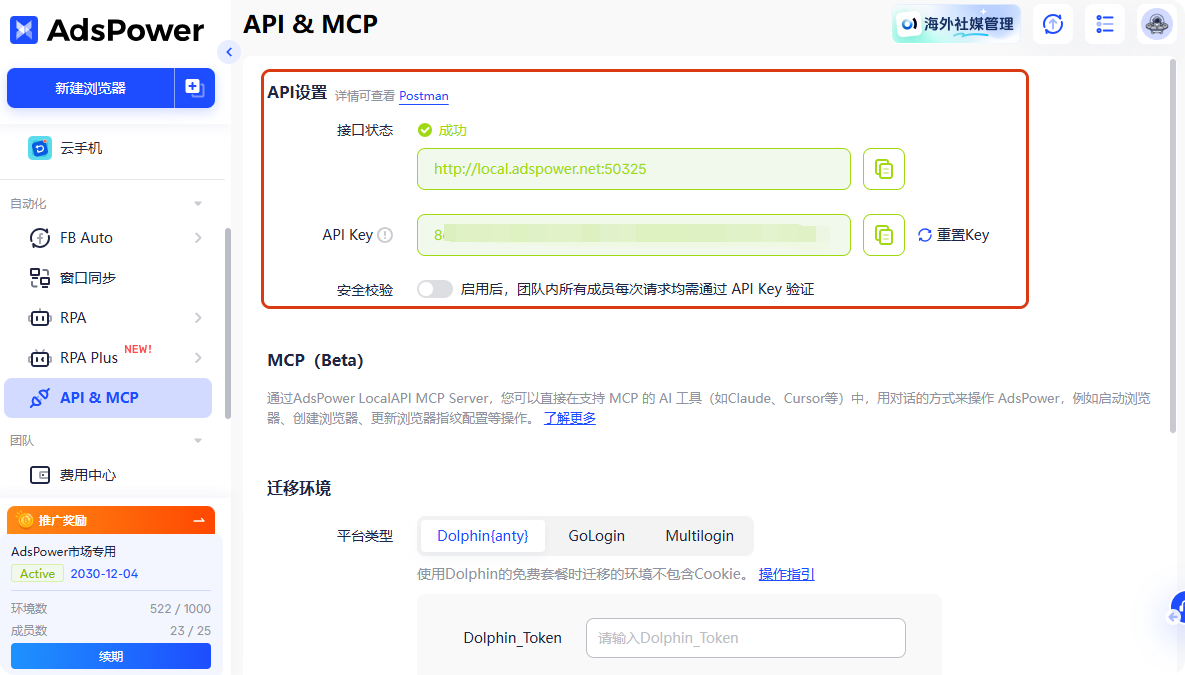
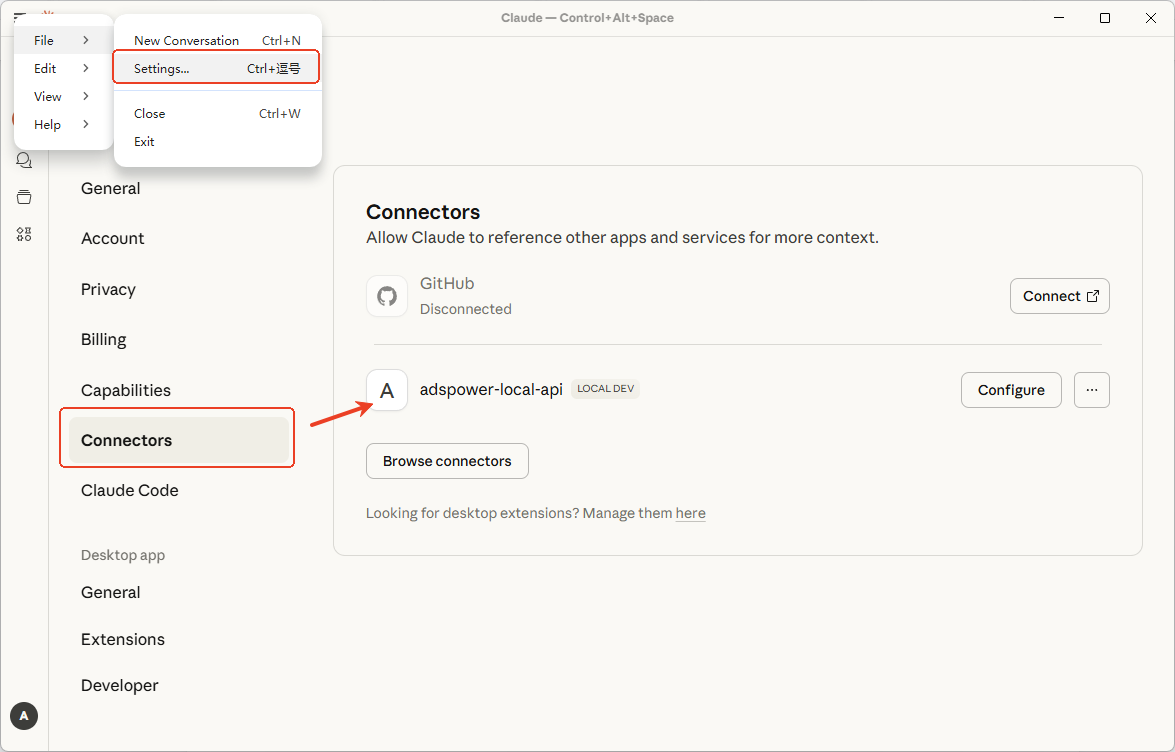
提供高效的自动化控制协议 (MCP)
AdsPower MCP Server 是 AdsPower 推出的一套自动化控制协议,托管在https://github.com/AdsPower/adspower-browser。它将 AdsPower Local API 的能力封装成 MCP协议工具,这样 Claude Code、Cursor、Codex、OpenCode 等先进的 AI 代码助手和大型语言模型就可以直接调用 AdsPower 浏览器能力。MCP 协议赋能 AI Agent 直接理解自然语言指令,并将其转化为对浏览器实例的控制操作,真正实现 AI 驱动的浏览器自动化。
常见问题
什么是网页自动化?
网页自动化是指通过程序或工具自动执行与网页交互的任务。例如,自动填写表单、抓取数据、导航网页等。它可以显著提高工作效率,特别是对于重复性的网页操作,避免了人工执行时的错误与耗时。
网页自动化的核心原理是什么?
网页自动化的核心原理一般基于 DOM(文档对象模型)操作,通过解析网页结构并与元素进行互动来实现自动化。工具通常使用编程语言(如Python、JavaScript等),利用库(如Selenium、Puppeteer)来控制浏览器执行特定指令。
什么应用场景适合网页自动化?
网页自动化广泛应用于数据抓取、网站测试、表单提交、内容监控和竞争分析等。例如,电商网站可以自动获取产品价格,金融行业可定期抓取市场数据,测试团队可以自动化测试网站功能确保没有bug。
如何开始网页自动化?
要开始网页自动化,首先选择合适的自动化工具(如Selenium、Puppeteer等),安装对应的环境和库。接着,学习基本的编程技能,例如Python或JavaScript,然后尝试编写简单的脚本进行基本操作,逐步掌握复杂应用。
网页自动化的常见挑战有哪些?
网页自动化可能面临的一些挑战包括网页结构的变化(导致脚本失效)、需要处理的动态内容(如Ajax加载)、CAPTCHA验证以及网络延迟等。因此,编写健壮的代码和做好异常处理尤为重要。

人们还读过
- Claude 封号潮又来了,中国用户怎么做才能稳定使用Claude 不被封号?

Claude 封号潮又来了,中国用户怎么做才能稳定使用Claude 不被封号?
Claude 又迎来新一轮封号潮,中国用户如何稳定使用 Claude?本文分析 Claude 封号原因,并分享降低风控、提升账号稳定性的实用方法,帮助你长期使用 Claude。
- Snapchat广告指南:开户、广告类型及投放技巧

Snapchat广告指南:开户、广告类型及投放技巧
想开始Snapchat广告投放?本文从账户注册、广告创建、广告类型进行全面解析,并介绍如何管理多个Snapchat广告账户,帮助跨境电商和品牌出海团队提升广告效果与运营效率。
- AI Agent、自动化开发越来越火,哪些热门GitHub 项目值得了解?

AI Agent、自动化开发越来越火,哪些热门GitHub 项目值得了解?
AI Agent 和自动化开发持续升温,本文精选多个 GitHub 热门开源项目,涵盖浏览器自动化、Agent 框架、工作流编排等方向,帮助开发者快速了解最新趋势。
- 2026最新FB登录教程:如何在一台电脑上安全登录多个Facebook账号?

2026最新FB登录教程:如何在一台电脑上安全登录多个Facebook账号?
海外营销与跨境电商卖家如何在一台电脑上登录多个Facebook账号且不封号?本文为您解析2026最新脸书防关联登录指南,通过指纹浏览器技术实现底层硬件指纹伪装与独立IP隔离,助您安全高效管理多个Facebook账号资产。
- 出海工具终极生存手册:eSIM + 住宅IP + 指纹浏览器 + 虚拟卡完整指南

出海工具终极生存手册:eSIM + 住宅IP + 指纹浏览器 + 虚拟卡完整指南
了解出海业务常用工具组合,包括eSIM、住宅IP、指纹浏览器和虚拟卡。本文详解各工具作用、使用场景及搭配方式,帮助提升海外平台注册与运营效率。

